BAB VI
Distribusi Normal, Distribusi T, dan Distribusi F
A. Karakteristik Distribusi Probabilitas Normal
Distribusi probabilitas normal dan kurva
normal telah dikembangkan oleh DeMoivre (1733) dan Gauss (1777 – 1855)
dengan menurunkan persamaan matematis dan kurva normalnya. Oleh sebab
itu, kurva normal sering juga disebut kurva Gauss.

Beberapa karakteristik dari distribusi probabilitas dan kurva normal adalah:
Bila X suatu pengubah acak normal dengan nilai tengah μ, dan standar deviasi σ, maka persamaan kurva normalnya adalah:

B. Jenis-jenis Distribusi Probabilitas Normal
Bentuk distribusi probabilitas dan kurva
normal dengan nilai tengah sama dan standar deviasi yang berbeda, adalah
bentuk leptokurtic, platykurtik dan mesokurtik. Kurva normal tersebut
mempunyai μ = Md = Mo yang sama, namun mempunyai σ berbeda. Semakin
besar σ, maka kurva semakin pendek dan semakin tinggi nilai σ, maka
semakin runcing. Oleh sebab itu, σ tinggi cenderung menjadi platykurtik
dan σ rendah menjadi leptokurtik. Nilai σ yang tinggi menunjukkan bahwa
nilai data semakin menyebar dari nilai tengahnya (μ). Apabila σ rendah,
maka nilai semakin mengelompok pada nilai tengahnya.

Bentuk distribusi probabilitas dan kurva
normal dengan μ berbeda dan σ sama mempunyai jarak antara kurva yang
berbeda, namun bentuk kurva tetap sama. Hal demikian bisa terjadi karena
kemampuan antar populasi berbeda, namun setiap populasi mempunyai
keragaman yang hampir sama.

Distribusi kurva normal dengan μ dan σ
berbeda. Kurva ini mempunyai titik pusat yang berbeda pada sumbu
mendatar dan bentuk kurva berbeda karena mempunyai standar deviasi yang
berbeda.
 C. Distribusi Probabilitas Normal Baku
 Z = Skor Z atau nilai normal baku X = Nilai dari suatu pengamatan atau pengukuran μ= Nilai rata-rata hitung suatu distribusi
σ= Standar deviasi
Contoh Soal:
Rata-rata berat sebuah kotak adalah 283
gram dan standar deviasinya 1,6 gram. Berapakah probabilitas sebuah
kotak dibawah 284,5 gram ?
 
Transformasi dari X ke Z
 Bila nilai X berada di antara X = x1 dan X = x2, maka variabel acak Z akan berada di antara nilai: 
Transformasi ini juga mempertahankan luas di bawah kurvanya, artinya:
 
Kurva setiap distribusi peluang
kontinu atau fungsi padat dibuat sedemikian rupa sehingga luas di bawah
kurva di antara kedua ordinat x = x1 dan x = x2 sama dengan peluang acak
X mendapatkan harga antara x = x1 dan x = x2. Luas di bawah kurva
antara dua ordinat sembarang tergantung pada harga µ dan σ.
Luas antara nilai Z (-1<Z<1) sebesar 68,26% dari jumlah data.
Berapa luas antara Z antara 0 dan sampai Z = 0,76 atau biasa dituis P(0<Z<0,76)?
Dapat dicari dari tabel luas di bawah kurva normal. Nilainya dihasilkan = 0,2764
E. Penerapan Kurva Normal
Contoh Soal 1
PT GS mengklaim rata-rata berat buah
mangga “B” adalah 350 gram dengan standar deviasi 50 gram. Bila berat
mangga mengikuti distribusi normal, berapa probabilitas bahwa berat buah
mangga mencapai kurang dari 250 gram, sehingga akan diprotes oleh
konsumen.
 Jawab:
Transformasi ke nilai z
AP(x< 250); P(x=250) = (250-350)/50=-2,00 Jadi P(x<250)=P(z<-2,00)
Lihat pada tabel luas di bawah kurva normal
P(z<-2,00)=0,4772
Luas sebelah kiri nilai tengah adalah
0,5. Oleh sebab itu, nilai daerah yang diarsir menjadi 0,5 –
0,4772=0,0228. Jadi probabilitas di bawah 250 gram adalah 0,0228
(2,28%). Dengan kata lain probabilitas konsumen protes karena berat buah
mangga kurang dari 250 gram adalah 2,28%.
Contoh Soal 2
PT Work Electric, memproduksi Bohlam Lampu yang dapat hidup 900 jam dengan standar deviasi 50 jam. PT Work Electric ingin mengetahui berapa persen produksi pada kisaran antara 800-1.000 jam, sebagai bahan promosi bohlam lampu. Hitung berapa probabilitasnya!  Jawab: P(800<X<1.000)?
Hitung nilai Z
Z1 = (800-900)/50 = -2,00;Z2 = (1.000-900)/50 = 2,00
Jadi: P(800<X<1.000) =P(-2,00<Z<2,00);
P(-2,00<Z) = 0,4772 dan P(Z>2,00) = 0,4772Sehingga luas daerah yang diarsir adalah = 0,4772+0,4772= 0,9544. Jadi P(800<X<1.000) = P(-2,00 < Z<2,00) = 0,9544. Jadi 95,44% produksi berada pada kisaran 800-1.000 jam. Jadi jika PT Work Electric mengklaim bahwa lampu bohlamnya menyala 800-1.000 jam, mempunyai probabilitas benar 95,44%, sedang sisanya 4,56% harus dipersiapkan untuk garansi. F. Pendekatan Normal Terhadap Binominal Apabila kita perhatikan suatu distribusi probabilitas binomial, dengan semakin besarnya nilai n, maka semakin mendekati nilai distribusi normal. Gambar berikut menunjukkan distribusi probabilitas binomial dengan n yang semakin membesar. 
Bila nilai X adalah distribusi acak binomial dengan nilai tengah μ = np dan standar deviasi σ = √npq, maka nilai Z untuk distribusi normal adalah:  di mana n >>>> ¥ dan nilai p mendekati 0,5 Faktor Koreksi Kontinuitas Nilai koreksi kontinuitas adalah sebesar 0,5 yang dikurangkan dan ditambahkan pada data yang diamati. Untuk mengubah pendekatan dari binomial ke normal, memerlukan faktor koreksi, selain syarat binomial terpenuhi: (a) hanya ada dua peristiwa, (b) peristiwa bersifat independen; (c) besar probabilitas sukses dan gagal sama setiap percobaan, (d) data merupakan hasil penghitungan. Menggunakan faktor koreksi yang besarnya 0,5. http://tekdig2011.blogspot.com/2012/05/distribusi-normal.html http://blog.ub.ac.id/adiarsa/tag/macam-distribusi/ http://asmauna.wordpress.com/tag/binomial/ http://mrfree793.blogspot.com/2012/06/distribusi-normal.html http://vebrianaparmita.wordpress.com/2013/11/10/bab-viii-distribusi-probabilitas-dan-kurva-normal/ |
Jumat, 18 April 2014
BAB VI Distribusi Normal, Distribusi T, dan Distribusi F
BAB V Momen, Kemiringan dan kurtosis
BAB 5
MOMEN, KEMIRINGAN DAN KURTOSIS
A.
Momen
Misal
diketahui variabel X dengan harga X1, X2, X3 . . .
. Xn. Jika A sebuah bilangan tetap dan r = 0, 1, 2,
3, maka momen di sekitar A disingkat
m’rdidefinisikan oleh
Dengan
Untuk menghitung momen disekitar
rata-rata, untuk data dalam daftar distribusi frekuensi, kita lakukan sebagai
berikut:
TABLE 5.1:
Table pembantu untuk mencari m
Data
|
f1
|
Ci
|
f1Ci
|
f1C12
|
f1C13
|
f1C14
|
60 – 63
64 – 67
68 – 71
72 – 75
76 – 70
|
5
18
42
27
8
|
-2
-1
0
1
2
|
-10
-18
0
27
16
|
20
18
0
37
42
|
-40
-18
0
27
64
|
80
18
0
27
128
|
Jumlah
|
100
|
15
|
97
|
35
|
253
|
Dapat dihitung
:
Jadi Varian S2 =
m2 = 15,16
B. Kemiringan
Kurva distribusi normal, yang tidak terlalu rucing atau tidak terlalu datar.
Dinamakanmesokurtik,
kurva yang runcing dinamakan leptokurtik sedangkan yang
datar disebutplatikurtik.
Salah satu ukuran kurtosis ialah
koefisien kurtosis, diberi simbol a4, ditentukan
dengan rumus a4 = (m4/m)
Kriteria yang didapat dari rumus
ini ialah:
a) a4 =
3 à Distribusi
normal
b) a4 >
3 à Distribusi
yagn leptokurtik
c) a4 <
3 à Distribusi
yang platikurtik
BAB IV UKURAN PENYIMPANGAN
TUGAS
STATISTIKA BAB 4
PENGUKURAN PENYIMPANGAN
Pengukuran penyimpangan adalah suatu
ukuran yang menunjukkan tinggi rendahnya perbedaan data yang diperoleh
dari rata-ratanya. Ukuran penyimpangan digunakan untuk mengetahui luas
penyimpangan data atau homogenitas data. Dua variabel data yang memiliki
mean sama belum tentu memiliki kualitas yang sama, tergantung dari besar
atau kecil ukuran penyebaran datanya. Ada bebarapa macam ukuran
penyebaran data, namun yang umum digunakan adalah standar deviasi.
Macam-macam ukuran penyimpangan data
adalah :
- Jangkauan (range)
- Simpangan rata-rata (mean deviation)
- Simpangan baku (standard deviation)
- Varians (variance)
- Koefisien variasi (Coefficient of variation)
1. Jangkauan (range)
Range adalah salah satu ukuran
statistik yang menunjukan jarak penyebaran data antara nilai terendah (Xmin)
dengan nilai tertinggi (Xmax). Ukuran ini sudah digunakan pada pembahasan
daftar distribusi frekuensi. Adapun rumusnya adalah
Contoh :
Berikut ini nilai ujian semester dari 3 mahasiswa
A = 60 55 70 65 50 80 40
B = 50 55 60 65 70 65 55
C = 60 60 60 60 60 60 60
Dari data diatas dapat diketahui bahwa
A = memiliki Xmax=80, Xmin= 40 , R = 40 , meanya 60
B = memiliki Xmax=70, Xmin= 50 , R = 20 , meanya 60
C = memiliki Xmax=60, Xmin= 60 , R = 0 , meanya 60
Dari contoh di atas dapat disimpulkan bahwa :
a. Semakin kecil rangenya maka semakin homogen distribusinya
b. Semakin besar rangenya maka semakin heterogen distribusinya
c. Semakin kecil rangenya, maka meannya merupakan wakil yang representatif
d. Semakin besar rangenya maka meannya semakin kurang representatif
2. Simpangan Rata-rata (mean deviation)
Simpangan rata-rata merupakan
penyimpangan nilai-nilai individu dari nilai rata-ratanya. Rata-rata bisa
berupa mean atau median. Untuk data mentah simpangan rata-rata dari median
cukup kecil sehingga simpangan ini dianggap paling sesuai untuk data mentah.
Namun pada umumnya, simpangan rata-rata yang dihitung dari mean yang sering
digunakan untuk nilai simpangan rata-rata.
- Data tunggal dengan seluruh skornya berfrekuensi satu
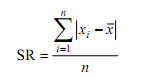
dimana xi
merupakan nilai data
- Data tunggal sebagian atau seluluh skornya berfrekuensi lebih dari satu
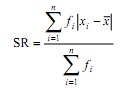
dimana xi
merupakan nilai data
- Data kelompok ( dalam distribusi frekuensi)
dimana xi
merupakan tanda kelas dari interval ke-i dan fi merupakan frekuensi
interval ke-i
Contoh :
Dari tabel diperoleh


3. Simpangan Baku (standard deviation)
Dari tabel diperoleh
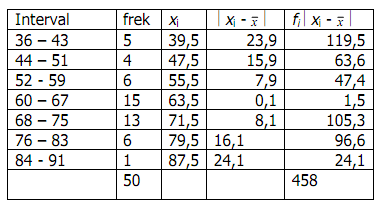
3. Simpangan Baku (standard deviation)
Standar deviasi merupakan ukuran
penyebaran yang paling banyak digunakan. Semua gugus data dipertimbangkan
sehingga lebih stabil dibandingkan dengan ukuran lainnya. Namun, apabila dalam
gugus data tersebut terdapat nilai ekstrem, standar deviasi menjadi tidak
sensitif lagi, sama halnya seperti mean.
Standar Deviasi memiliki beberapa
karakteristik khusus lainnya. SD tidak berubah apabila setiap unsur pada gugus
datanya di tambahkan atau dikurangkan dengan nilai konstan tertentu. SD berubah
apabila setiap unsur pada gugus datanya dikali/dibagi dengan nilai konstan
tertentu. Bila dikalikan dengan nilai konstan, standar deviasi yang dihasilkan
akan setara dengan hasilkali dari nilai standar deviasi aktual dengan konstan.
Rumus Simpangan Baku untuk Data
Tunggal
- untuk data sample menggunakan rumus
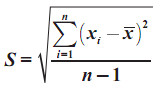
- untuk data populasi menggunkan rumus

Contoh :
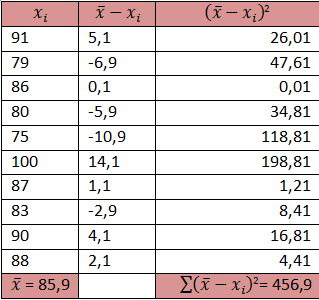
Selama 10 kali ulangan semester ini sobat mendapat nilai 91, 79, 86, 80, 75, 100, 87, 93, 90,dan 88. Berapa simpangan baku dari nilai ulangan sobat?
Selama 10 kali ulangan semester ini sobat mendapat nilai 91, 79, 86, 80, 75, 100, 87, 93, 90,dan 88. Berapa simpangan baku dari nilai ulangan sobat?
Jawab
Soal di atas menanyakan simpangan baku dari data populasi jadi menggunakan rumus simpangan baku untuk populasi.
Kita cari dulu rata-ratanya
rata-rata = (91+79+86+80+75+100+87+93+90+88)/10 = 869/10 = 85,9

Kita masukkan ke rumus
Soal di atas menanyakan simpangan baku dari data populasi jadi menggunakan rumus simpangan baku untuk populasi.
Kita cari dulu rata-ratanya
rata-rata = (91+79+86+80+75+100+87+93+90+88)/10 = 869/10 = 85,9
Kita masukkan ke rumus
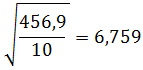
Rumus Simpangan Baku Untuk Data
Kelompok
- untuk sample menggunakan rumus
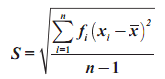
- untuk populasi menggunakan rumus

Contoh :
Diketahui data tinggi badan 50 siswa samapta kelas c adalah sebagai berikut
Diketahui data tinggi badan 50 siswa samapta kelas c adalah sebagai berikut
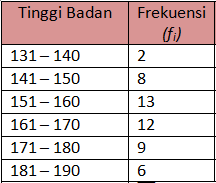
hitunglah berapa simpangan bakunya
1. Kita cari dulu rata-rata data kelompok tersebut

2. Setelah ketemu rata-rata dari data kelompok tersebut kita bikin tabel untuk memasukkannya ke rumus simpangan baku

4. Varians (variance)
1. Kita cari dulu rata-rata data kelompok tersebut

2. Setelah ketemu rata-rata dari data kelompok tersebut kita bikin tabel untuk memasukkannya ke rumus simpangan baku

4. Varians (variance)
Varians adalah salah satu ukuran
dispersi atau ukuran variasi. Varians dapat menggambarkan bagaimana
berpencarnya suatu data kuantitatif. Varians diberi simbol σ2 (baca:
sigma kuadrat) untuk populasi dan untuk s2 sampel.
Selanjutnya kita akan menggunakan
simbol s2 untuk varians karena umumnya kita hampir selalu
berkutat dengan sampel dan jarang sekali berkecimpung dengan populasi.
Rumus varian atau ragam data tunggal
untuk populasi
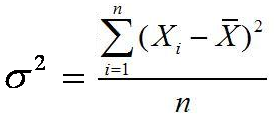
Rumus varian atau ragam data tunggal
untuk sampel
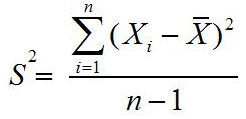
Rumus varian atau ragam data
kelompok untuk populasi
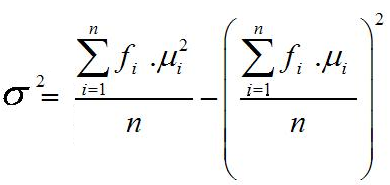
Rumus varian atau ragam data
kelompok untuk sampel
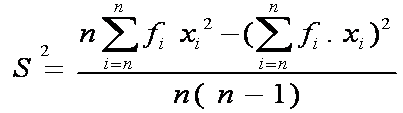
Keterangan:
σ2 = varians atau ragam untuk populasi
S2 = varians atau ragam untuk sampel
fi = Frekuensi
xi = Titik tengah
x¯ = Rata-rata (mean) sampel dan μ = rata-rata populasi
n = Jumlah data
σ2 = varians atau ragam untuk populasi
S2 = varians atau ragam untuk sampel
fi = Frekuensi
xi = Titik tengah
x¯ = Rata-rata (mean) sampel dan μ = rata-rata populasi
n = Jumlah data
5. Koefisien variasi (Coefficient
of variation)
Koefisien variasi merupakan suatu
ukuran variansi yang dapat digunakan untuk membandingkan suatu distribusi data
yang mempunyai satuan yang berbeda. Kalau kita membandingkan berbagai variansi
atau dua variabel yang mempunyai satuan yang berbeda maka tidak dapat dilakukan
dengan menghitung ukuran penyebaran yang sifatnya absolut.
Koefisien variasi adalah suatu
perbandingan antara simpangan baku dengan nilai rata-rata dan dinyatakan dengan
persentase.

Besarnya koefisien variasi akan
berpengaruh terhadap kualitas sebaran data. Jadi jika koefisien variasi
semakin kecil maka datanya semakin homogen dan jika koefisien korelasi semakin besar
maka datanya semakin heterogen.
DAFTAR PUSTAKA
http://vebrianaparmita.wordpress.com/2013/10/06/bab-vi-pengukuran-penyimpangan-range-deviasi-varian
Sudjana. (1991). In Statistika. Bandung:
Tarsito.
http://www.smartstat.info/statistika/statisika-deskriptif/ukuran-penyebaran-measures-of-dispersion.html
http://rumushitung.com/2013/04/05/rumus-simpangan-baku/
http://digensia.wordpress.com/2012/03/15/statistik-deskriptif/
http://okemath.com/?page_id=394
http://www.smartstat.info/statistika/statisika-deskriptif/ukuran-penyebaran-measures-of-dispersion.html
http://rumushitung.com/2013/04/05/rumus-simpangan-baku/
http://digensia.wordpress.com/2012/03/15/statistik-deskriptif/
http://okemath.com/?page_id=394
Langganan:
Postingan (Atom)